
搭建Spark分布式集群 |
SuperMap iServer 提供的产品包均内置了 Spark 安装包,您也可以自行将 Spark 分布式集群搭建在其他机器上,注意:Spark 的版本需要与 iServer 内置的一致,同时,Hadoop 版本也需要与其对应。当前 iServer 内置 Spark 版本为 spark-3.3.0-bin-hadoop3,因此使用的 Hadoop 版本应为 3.x 。以下将介绍如何在 Linux 平台上搭建 Spark 分布式集群。
本示例采用 Ubuntu 18.04 操作系统,作为 Spark 分布式集群的 Master 节点,自身又作为 Worker 节点。IP 为 Master:192.168.217.141。
注意:用户配置环境之前,可查看 iServer 根目录\support\spark\RELEASE 文件确定适配的 spark+hadoop 版本要求。
搭建 Spark 分布式集群环境需要配置 Java 环境(JDK 下载地址http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html#javasejdk,建议使用 JDK 8及以上版本)、配置 SSH 以及 Spark(下载地址:http://spark.apache.org/downloads.html)。
本示例使用的软件为:
下面以 Master 节点为例,介绍 Spark 集群搭建流程,Worker 节点与此相同。
所有操作需要以 root 用户执行。通过如下命令可由普通用户切换至 root 用户:
sudo -i
再次输入当前用户密码即可。
Spark 分布式集群系统默认使用到以下端口,因此需要修改防火墙配置开放这些端口:
检查端口开放状态:
ufw status
开放端口命令如下:
ufw allow [port]
[port]为将开放的端口号。例如:
ufw allow 8080
本例将已下载的 JDK 包存放在/home/supermap/中
解压 JDK 包
tar -xvf jdk-8u171-linux-x64.tar.gz
在/usr/lib/目录下新建java文件夹:
mkdir /usr/lib/java
将已解压的 JDK 文件夹复制或移至“/usr/lib/java”中,如:
cp -r /home/supermap/jdk-8u171-linux-x64/usr/lib/java
配置 Java 环境变量,输入如下命令打开环境变量配置文件:
vi /etc/profile
按下“i”开始编辑。在配置文件末尾写入如下配置:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
按下“esc”退出编辑模式,再输入“:wq”保存并退出文件编辑。
输入如下命令使环境变量配置生效:
source /etc/profile
检验Java是否安装成功:
java -version
正确显示已安装的 Java 版本信息时,表示安装成功。
Spark 采用 SSH 进行通信,外网环境下可直接输入如下命令为当前系统安装 SSH。
apt-get install open-ssh
内网环境需使用文件传输工具,如 XManager,将已下载的 .deb 包传至虚拟机进行安装,安装命令如:
dpkg -i /home/supermap/openssh-server_7.6p1-4ubuntu0.5_amd64.deb
查看 ssh 是否安装成功:
ps -e|grep ssh
显示如下信息表示 SSH 安装成功
为方便操作,通过配置 SSH 无密码验证,实现各节点间的无密码通信。
生成密钥,其中,'' 表示两个单引号:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
此时,在 /root/.ssh 中生成了两个密钥文件:id_dsa和id_dsa.pub,其中id_dsa为私钥,id_dsa.pub 为公钥。
需要将 id_dsa.pub 追加到 authorized_keys 中,authorized_keys 用于保存所有允许以当前用户身份登录到 ssh 客户端用户的公钥内容:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
查看现在能否免密码登录 SSH:
ssh localhost
输入“yes”继续登录。完成后,输入 “exit”退出 localhost。再次登录使就不需要密码了。
以同样的步骤在 Worker 节点中配置。
要实现各节点间免密码通信,需要将 Worker 中生成的公钥拷贝到 Master 中,Master 再将该公钥追加到 authorized_keys。
在 Worker1 中,将公钥拷贝到 Master :
scp id_rsa.pub root@192.168.217.141:/root/.ssh/id_rsa.pub.Worker1
在 Worker2 中,将公钥拷贝到 Master :
scp id_rsa.pub root@192.168.217.141:/root/.ssh/id_rsa.pub.Worker2
Master 中将公钥追加到 authorized_keys:
cat ~/.ssh/id_rsa.pub.Worker1 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub.Worker2 >> ~/.ssh/authorized_keys
Master 将 authorized_keys 拷贝到两个 Worker 节点中:
scp ~/.ssh/authorized_keys root@192.168.217.137:/root/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@192.168.217.138:/root/.ssh/authorized_keys
此时,Master 与两台 Worker 通信时就不需要密码了。
下载 Spark 安装包,存放在/home/supermap/中
解压已下载的 Spark 包:
tar -xvf spark-3.3.0-bin-hadoop3.tgz
在/usr/local/目录下新建spark文件夹:
mkdir /usr/local/spark
把解压后的"spark-3.3.0-bin-hadoop3"复制到“/usr/local/spark”中:
cp -r /home/supermap/spark-3.3.0-bin-hadoop3/ /usr/local/spark
配置第三方依赖
在 iServer 根目录\support\spark\jars 下找到 kafka-clients-2.8.1.jar 、spark-streaming-kafka-0-10_2.12-3.3.0.jar 两个三方依赖包,将依赖包复制至 ' /usr/local/spark/spark-3.3.0-bin-hadoop3/jars' 下:
cp -r /home/supermap/kafka-clients-2.8.1.jar/ /usr/local/spark/spark-3.3.0-bin-hadoop3/jars
cp -r /home/supermap/spark-streaming-kafka-0-10_2.12-3.3.0.jar/ /usr/local/spark/spark-3.3.0-bin-hadoop3/jars
导入 UGO 配置
在 /usr/local/spark/ 目录下新建 objectsjava 文件夹:
mkdir /usr/local/spark/objectsjava
在 iServer 根目录 \support\objectsjava\ 下找到 bin,将整个 bin 文件夹拷贝到 /usr/local/spark/objectsjava 下。
配置 Spark 环境变量
输入如下命令打开环境变量配置文件:
vi /etc/profile
按下“i”开始编辑。在配置文件末尾添加如下配置:
export SPARK_HOME=/usr/local/spark/spark-3.3.0-bin-hadoop3
同时将bin目录加入PATH中,写入后结果如下:
export PATH=${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin:$JRE_HOME/bin:${SPARK_HOME}/bin:$PATH
按下“esc”退出编辑模式,再输入“:wq”保存并退出文件编辑。
输入如下命令使环境变量配置生效:
source /etc/profile
Spark 集群Master节点配置
进入 Spark 配置文件目录:
cd /usr/local/spark/spark-3.3.0-bin-hadoop3/conf
当前目录下没有 spark-env.sh文件,需要将 spark-env.sh.template 修改为spark-env.sh。使用如下命令,spark-env.sh.template 复制到spark-env.sh:
cp spark-env.sh.template spark-env.sh
打开 spark-env.sh 文件
vi spark-env.sh
按下“i”进入编辑模式,在文件末尾添加如下配置
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
export JAVA_HOME=/usr/lib/java/jdk1.8.0_171
export SPARK_MASTER_HOST=192.168.217.141
export SPARK_MASTER_PORT=7077
export UGO_HOME=/usr/local/spark/objectsjava/
export LD_LIBRARY_PATH=$UGO_HOME/bin:$LD_LIBRARY_PATH
export PATH=$JAVA_HOME/bin:$LD_LIBRARY_PATH:$PATH
其中:
此外,您还可以指定Master节点、Worker节点使用的端口、访问Master Web UI的端口等。
如果您需要自定义端口,请检查防火墙是否已开放此端口。
按下“esc”退出编辑模式,再输入“:wq”保存并退出文件编辑。
修改主机名
此步骤可参考修改主机名。
Spark 集群Worker节点配置
Spark 集群各Worker节点需要在 workers 文件进行配置,Spark 安装包中不直接提供 workers 文件,而是在配置文件目录中提供了 workers.template,因此生成 workers 文件的方式与 spark-env.sh 相同:
cp workers.template workers
打开 workers 文件
vi workers
将默认的节点“localhost”删除,输入 Spark 集群各节点的主机名称:
sparkmaster
三个节点的配置内容相同。保存并退出编辑。
启动 Master 节点
在 Master 节点所在机器依次执行以下命令:
cd /usr/local/spark/spark-3.3.0-bin-hadoop3.tgz/sbin
./start-all.sh
其中,
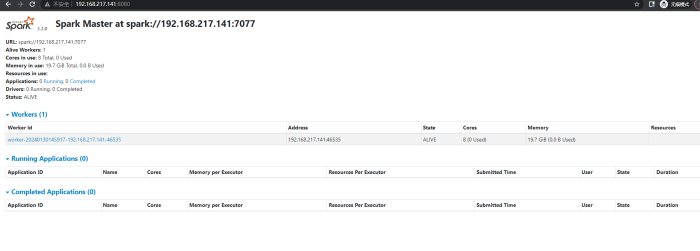
启动后,在浏览器中输入http://sparkmaster:8080 即可查看集群情况。
为了更安全地在 iServer 中使用 standalone 类型的 Spark 集群,iServer 提供了安全配置,并能够在开启集群和使用集群处理任务(如使用分布式分析服务、流数据服务、处理自动化服务)时使用相同密钥保证任务的执行。您可以在 %SuperMap iServer_HOME%/support/spark/conf/spark-defaults.conf 进行设置,添加如下代码:
spark.authenticate true
spark.authenticate.secret secret
其中,spark.authenticate 用于开启该安全配置,默认为 false,即不开启;spark.authenticate.secret 用于设置自定义安全密钥,可设置为任意字符串。
请注意: